 M3: Matryoshka Multimodal Models
M3: Matryoshka Multimodal Models
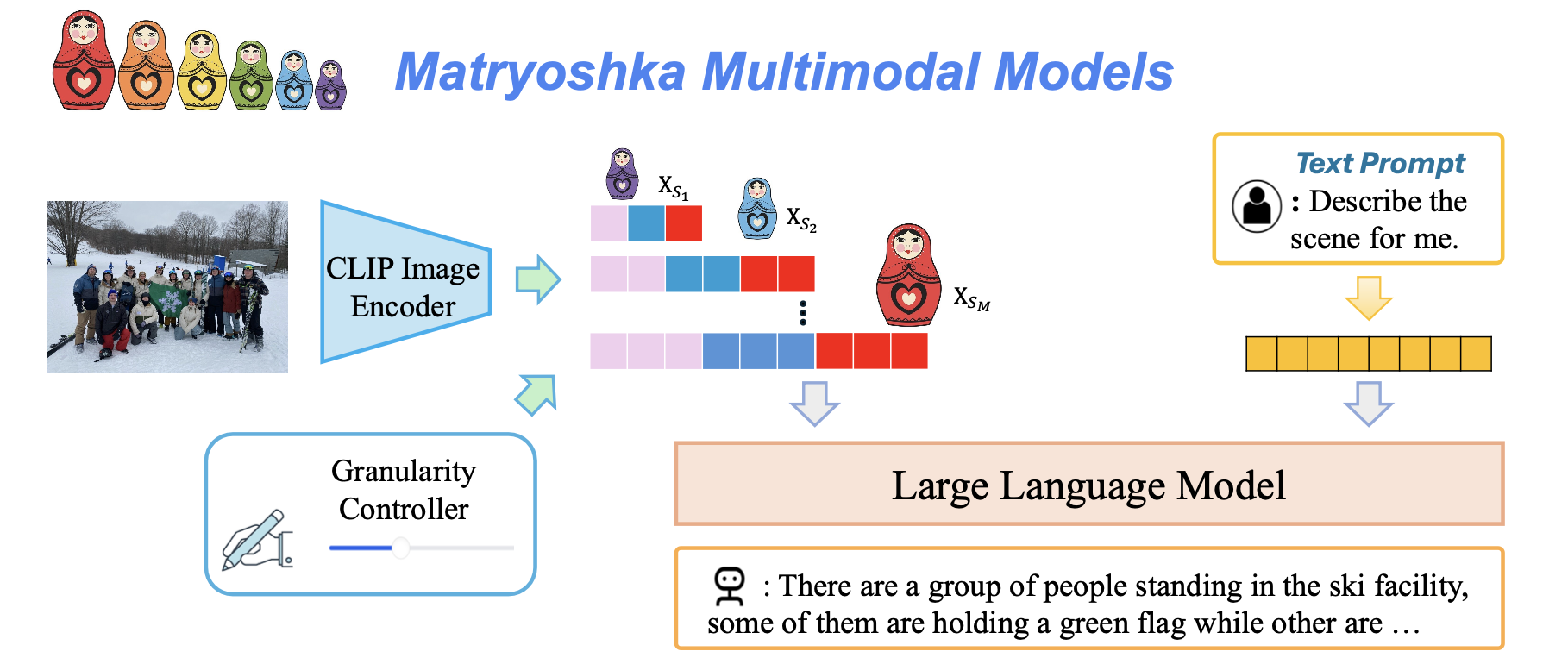
M3 enables LMMs to learned a nested representation of visual tokens in a coarse-to-fine manner. Our approach shows several benefits:
- Simple Design. We use the vanilla LMM architecture and training data. Only need to add a few lines of code. No visual scale encoding module is needed.
- Controllability. One can explicitly control the visual granularity per test instance during inference, e.g. , adjusting the number of tokens used to represent an image.
- Dataset analyzing tool. M3 provides a framework for analyzing the granularity needed for existing datasets, where we find that COCO-style benchmarks only need around ~9 visual tokens to obtain accuracy similar to that of using all 576 tokens.
- Foundation for the visual token reduction task. Our approach provides a foundation to explore the best trade-off between performance and visual token length at sample level, where our investigation reveals that a large gap exists between the oracle upper bound and current fixed-scale representations.

Our training is very simple. We take the average of the language generation loss over diverse visual token scales. In our paper, we use average pooling to get the multi-granularities visual tokens.
 Main Results
Main Results
 M3 maintains the performance of vanilla LMMs even under few visual tokens
M3 maintains the performance of vanilla LMMs even under few visual tokens
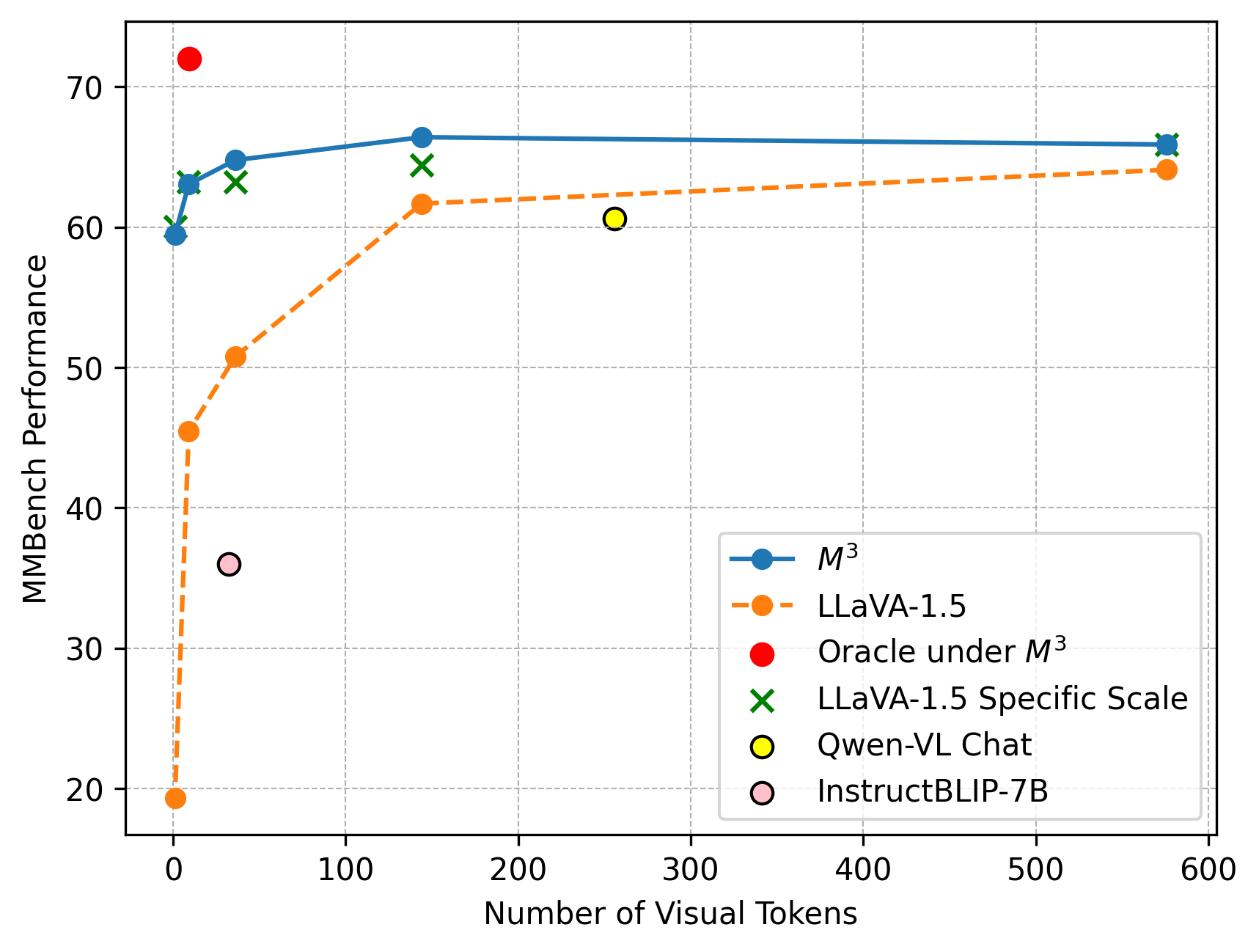
Above figure shows the performance comparsion between LLaVA-1.5-7B-M3 and various baselines in MMBench, where we can find
- M3 maintains the performance of LMM trained on a specific scale. Under one suite of LMM weights, the performance of M3 under diverse scales is at least as good as LLaVA-1.5 trained on a specific scale.
- Inference-time heuristics shows far less desirable performance. We directly apply average pooling on LLaVA's visual tokens at inference. Performance drops significantly with number of visual tokens decreasing. More study on spatial and sequential sampling is shown in the paper.
- Oracle is far better than the performance curve under specific scales. Oracle denotes the case where the best tradeoff between visual tokens and performance is picked. More efforts are needed to drag us towards the oracle points
- M3 under 9 visual tokens is still better than baselines such as InstructBLIP or Qwen-VL. .
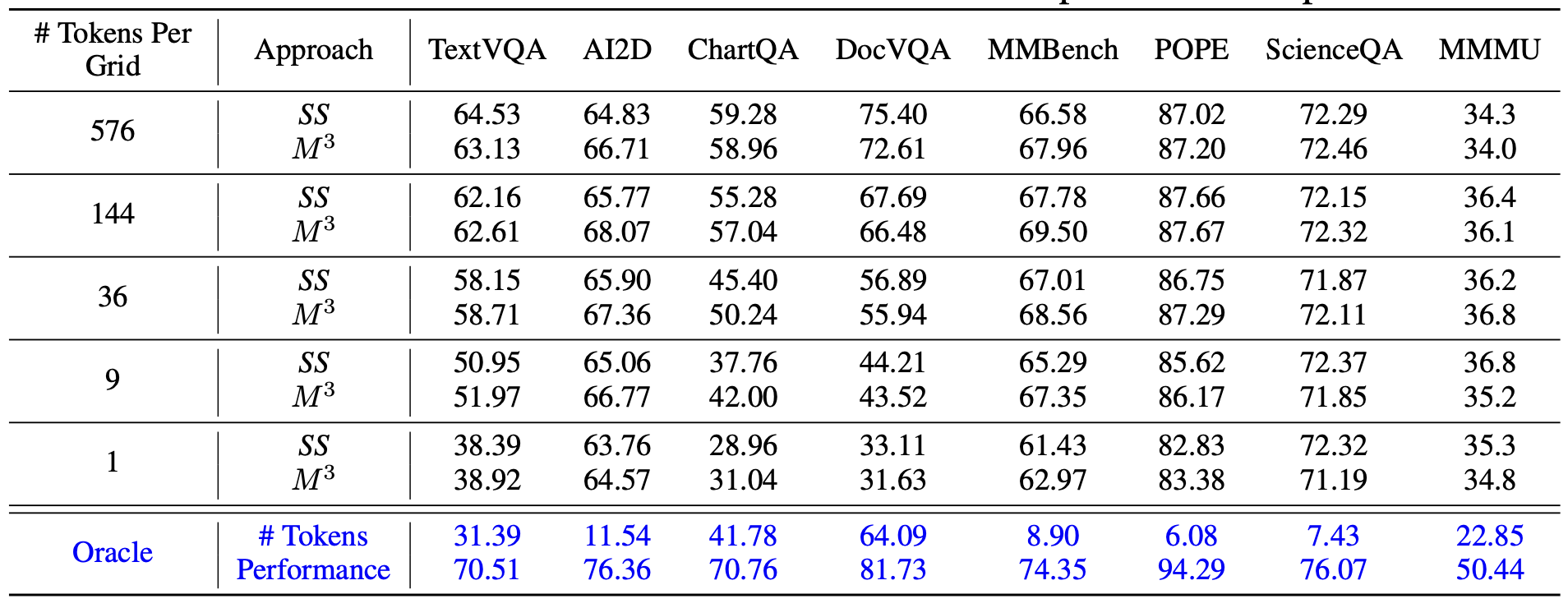
 For certain benchmarks, 9 tokens are enough per image (grid)
For certain benchmarks, 9 tokens are enough per image (grid)
Table below shows the performance comparsion between LLaVA-Next-7B-M3 and various baselines in MMBench, where we can find
- Dataset level biases towards the visual token scales do exist. ScienceQA maintains consistent performance across all visual token scales. AI2D and MMBench only encounter a small performance drop for even as few as 9 to 1 tokens. On the other hand, dense visual perception tasks such as TextVQA and DocVQA show a significant performance drop with fewer tokens.
- Using full tokens cannot always result in the optimal performance for all samples. This indicates that using full tokens cannot always result in the optimal performance for all samples; i.e., there is a large room of improvement towards the oracle point.
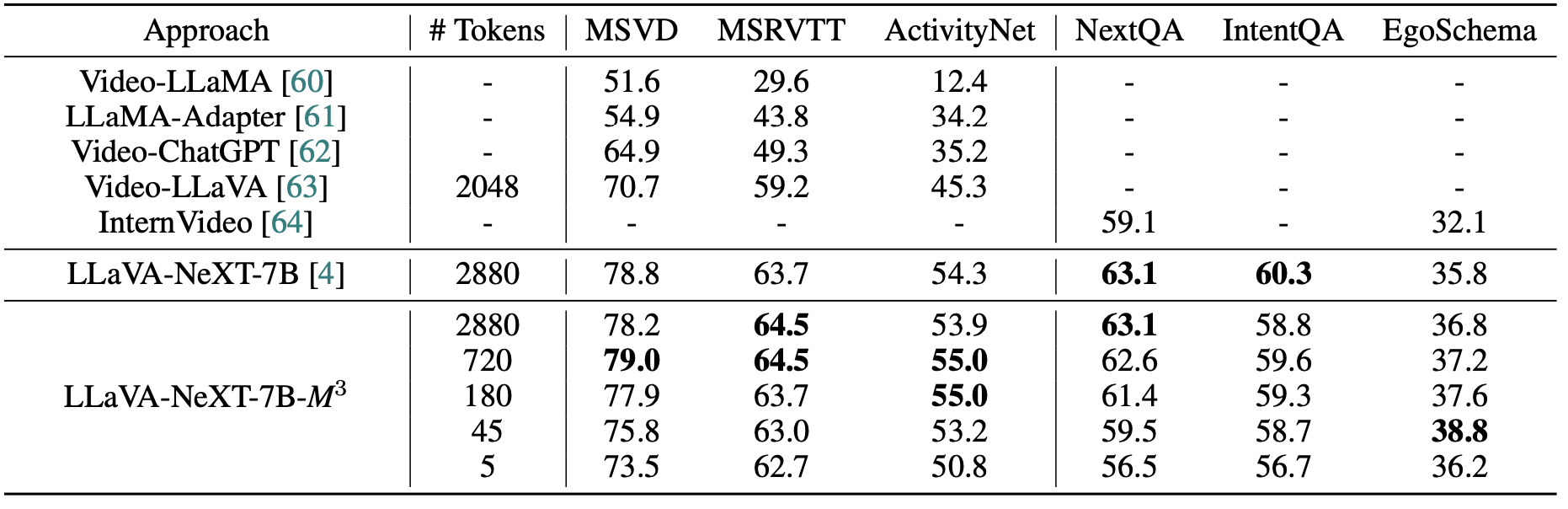
Most video understanding benchmarks show similar performance with 1.6% visual tokens
Table below shows the performance under LLaVA-1.5-7B-M3 and various baselines in MMBench, where we can find
- Full visual tokens usually do not lead to the best performance in video understanding tasks. On 4 out of 6 benchmarks, full visual tokens show less desirable performance compared to 720 or 180 visual tokens. We suspect that very long visual context could bring distraction to the model’s prediction.
- Most video understanding benchmarks only need a few visual tokens. Most video understanding tasks such as ActivityNet, IntentQA and EgoSchema, with 9 tokens per image grid (45 tokens in total), the accuracy difference compared to full tokens (2880 in total) is less than 1%. This demonstrates that the video questions in these benchmarks usually require very sparse visual information, as the source of such video understanding benchmarks mostly comes from natural scenes, which matches our observation in image understanding benchmarks.
 Interesting Findings
Interesting Findings
M3 serves as a good metric for image complexity
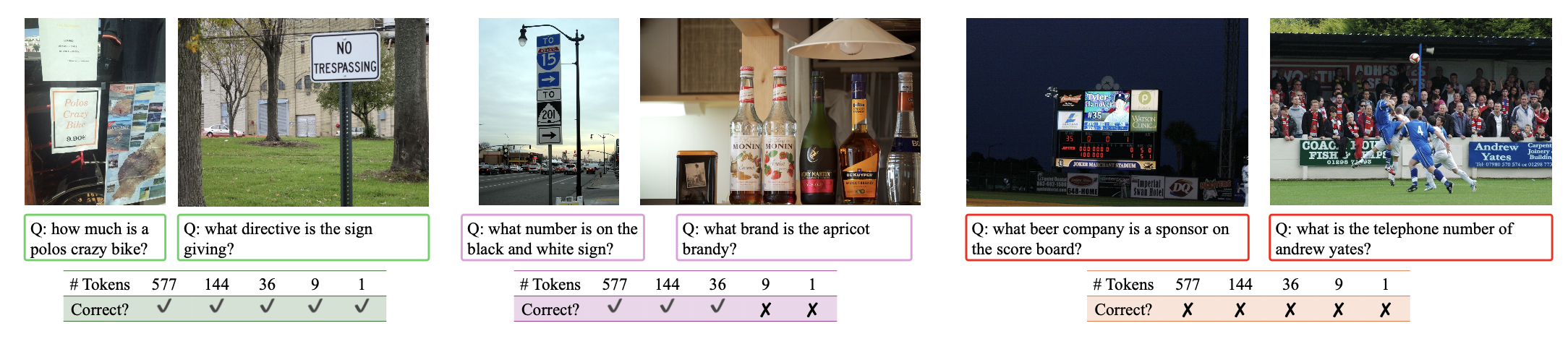
We extract the response from LLaVA-NeXT-M3 in the TextVQA benchmark, and show the samples where using visual tokens across different scales can answer the question correctly and incorrectly. Shown in the figure above, the OCR performance aligns with the complexity of the images, which indicates that M3 can be utilized as a metric towards sample level complexity.
More visualizations on nested visual representation

Shown in Figure above, with more visual tokens, LMMs can discover more details, such as furniture and human attributes. Besides, LMMs can generate higher quality descriptions with more visual tokens, as demonstrated by the OCR capability in (b).
BibTeX
@article{cai2024matryoshka,
title={Matryoshka Multimodal Models},
author={Cai, Mu and Yang, Jianwei and Gao, Jianfeng and Lee, Yong Jae},
journal={Proceedings of the International Conference on Learning Representation},
year={2025}
}
Acknowledgement
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the LLaMA team for giving us access to their models, and open-source projects, including Alpaca and Vicuna.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
Related Links: [LLaVA] [Insutrction Tuning with GPT-4]